
The Illusion of Control
Why the jump from vibe coding to agentic engineering isn't about better prompts. It's about building a harness: the constraints, detection, and verification that run around the agent, not inside it.
Writing on agentic engineering, AI coding workflows, and building software with multi-agent systems.
Why the jump from vibe coding to agentic engineering isn't about better prompts. It's about building a harness: the constraints, detection, and verification that run around the agent, not inside it.
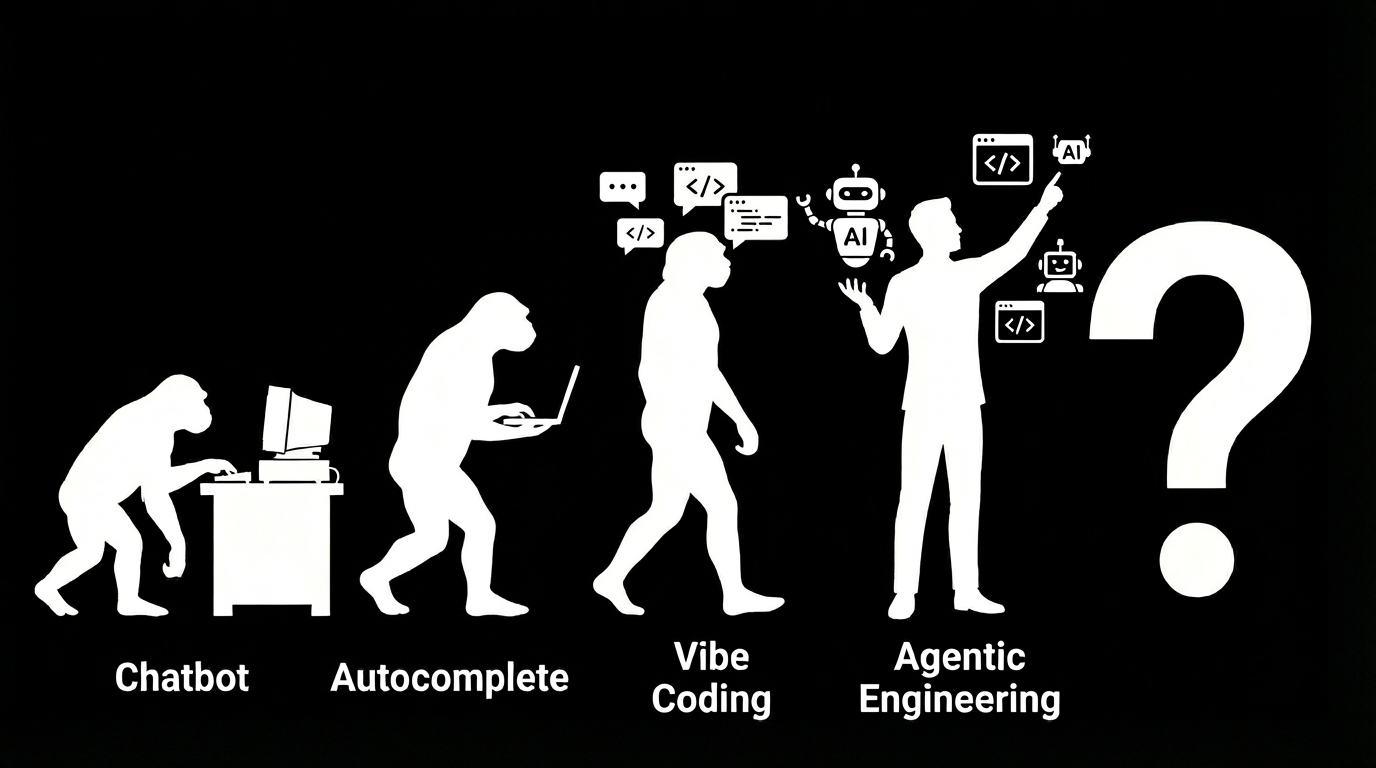
Where are you on the AI evolution chart? Most people are stuck between Autocomplete and Vibe Coding. The jump to Agentic Engineering requires changing your behavior, not your tools.
Why writing a great prompt isn't controlling your AI agents. An ELI5 on agent harnesses: the boundaries that run before, during, and after every action.

Why encoding rules into types, linters, and permission gates beats documentation when managing 100+ AI agents.
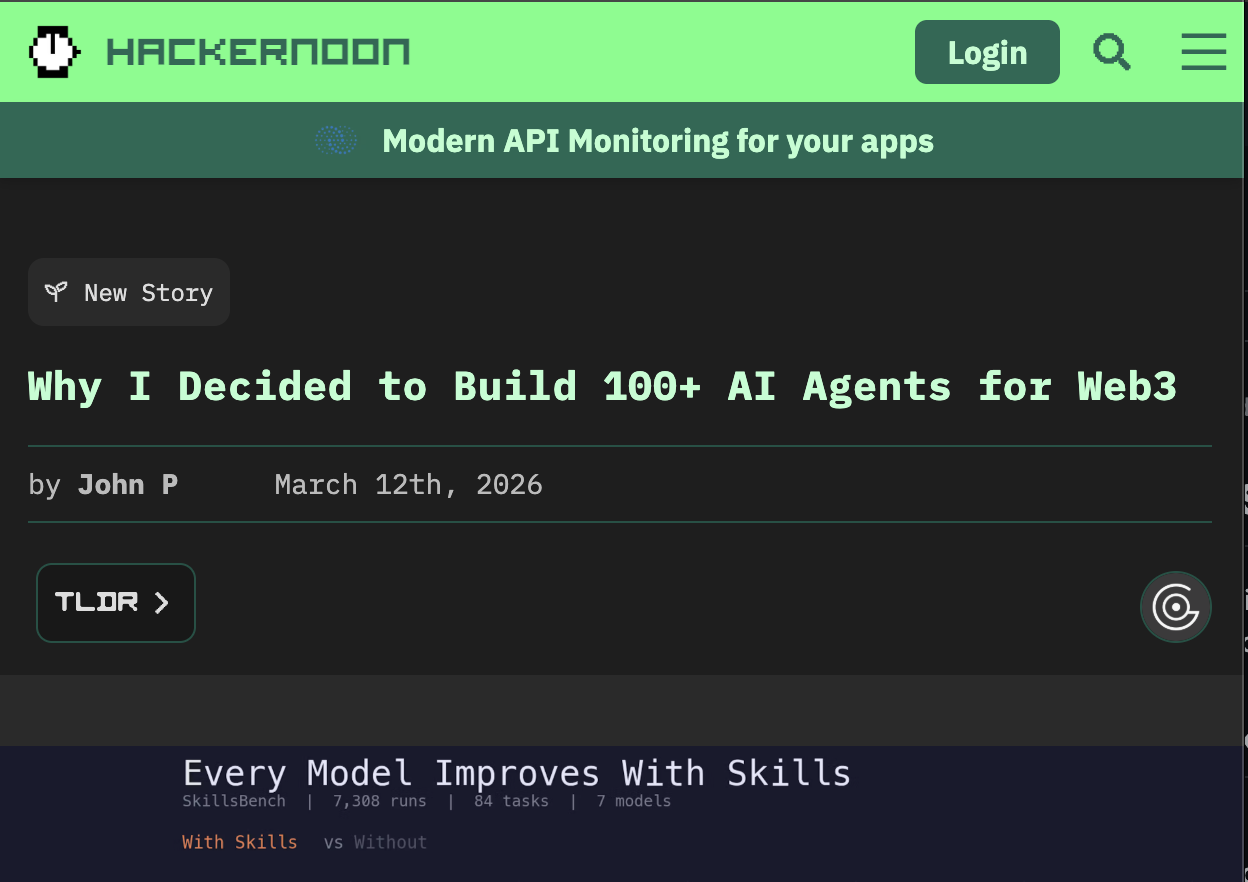
Why 100+ agents isn't complexity. How skills (precompiled expertise in markdown) became the highest-leverage intervention in an agent system, backed by SkillsBench data.
AI training has three stages: pre-training builds capability, RL Know refines judgment, RL Do trains action. That last one is why AI feels different now.
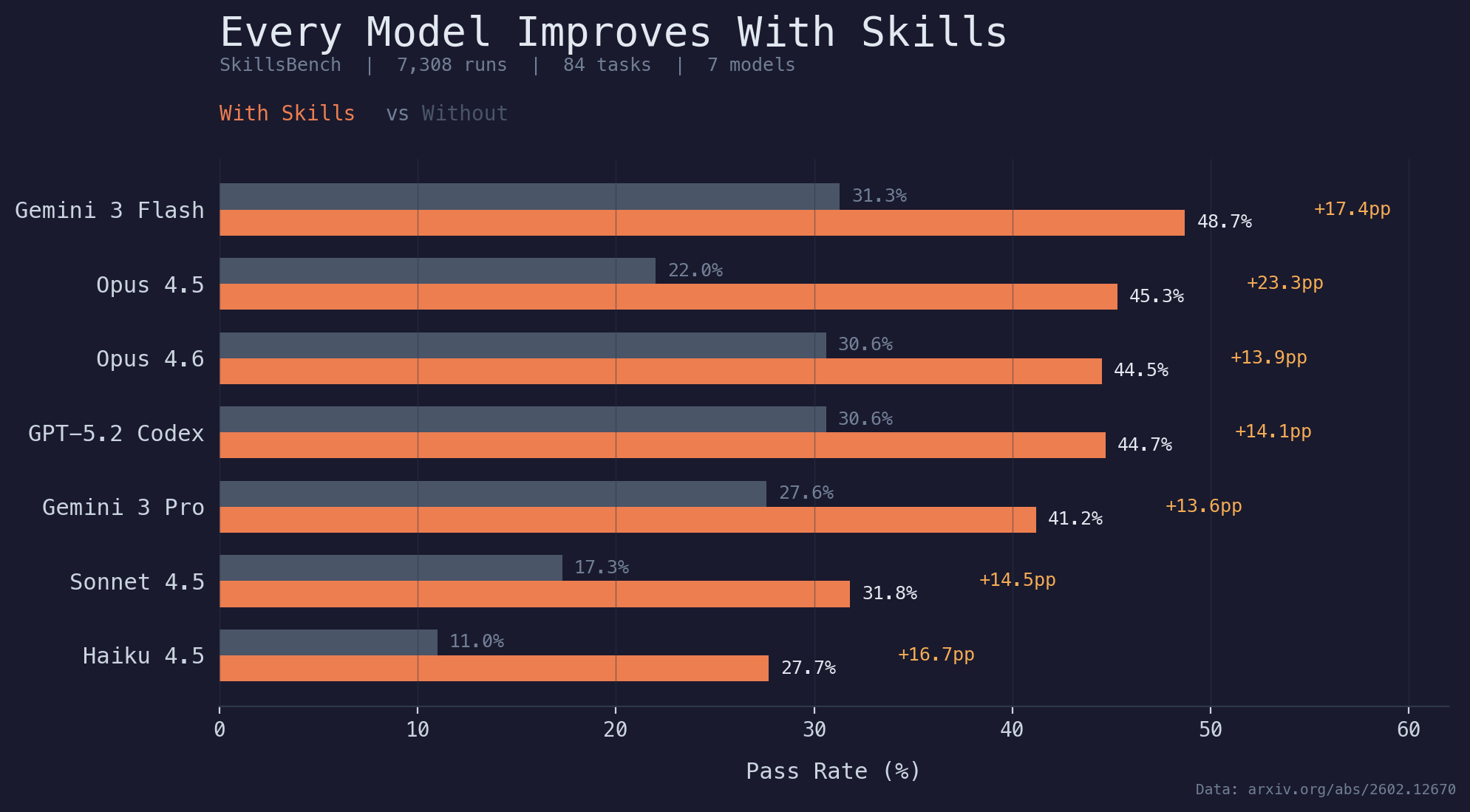
SkillsBench tested 7,308 agent runs. The data confirms: good engineering -- focused skills -- consistently improves agent outcomes.
The full synthesis: context rot, DRYP, skills vs. agents, and why good practice -- not grand design -- is how you get to 100+.
Applying the DRY principle to AI agent instructions: why duplicated prompts are a refactoring opportunity.

Five non-negotiable rules for moving from vibe coding to real AI agentic software engineering.
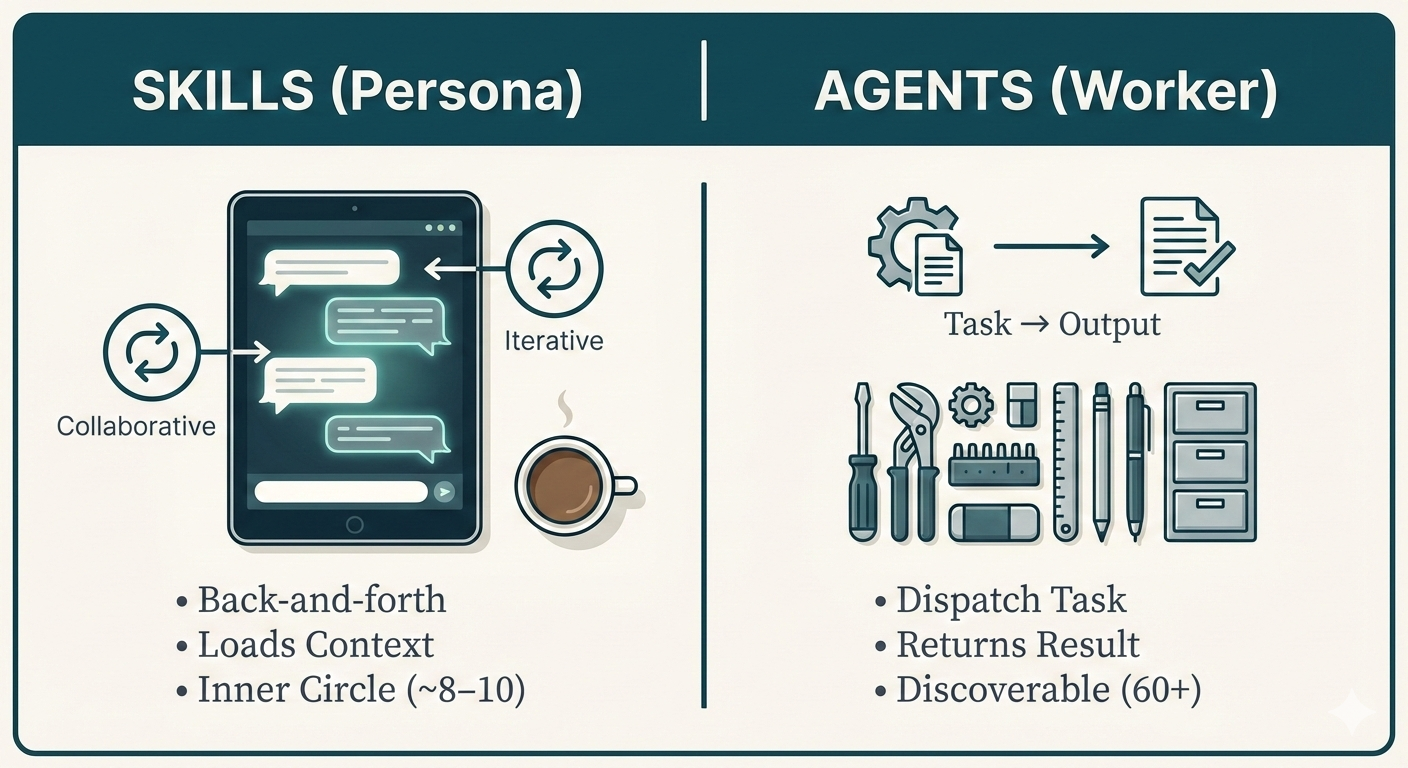
The framework that made 70+ AI agents manageable: the distinction between skills and agents.
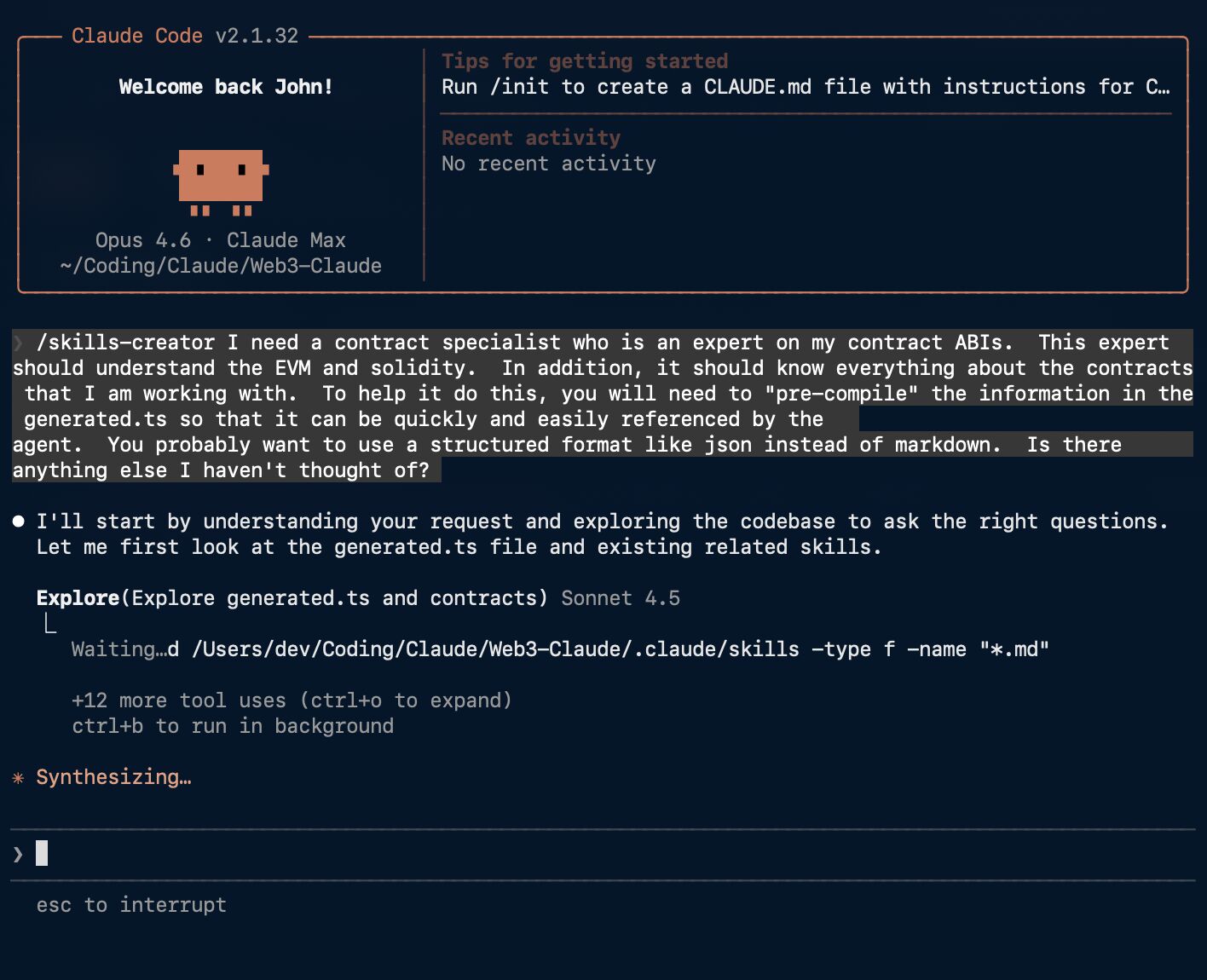
Why stuffing AI with more context makes results worse, and how a skills-specialist agent fixes it.