Failures Become Guardrails
It's only failure if you don't learn from it. The viral k10s post is making me think of that line, because it is fine to learn from the same failure in two different ways.
Writing on agentic engineering, AI coding workflows, and building software with multi-agent systems.
It's only failure if you don't learn from it. The viral k10s post is making me think of that line, because it is fine to learn from the same failure in two different ways.
The argument was never AI or no AI. It was what kind of work you are asking AI to do. That is why this 1983 Pascal satire still works.
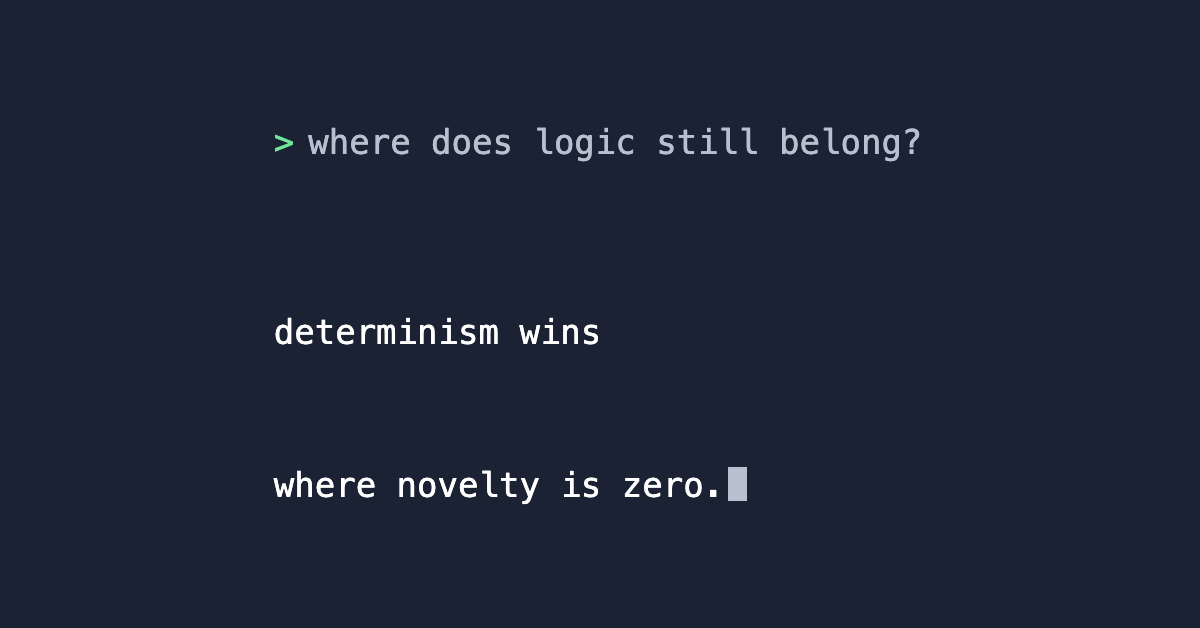
Determinism wins where there is nothing new to decide. The first practical answer to the problem in my last post: probability belongs where there is novelty, not where the answer is already known.
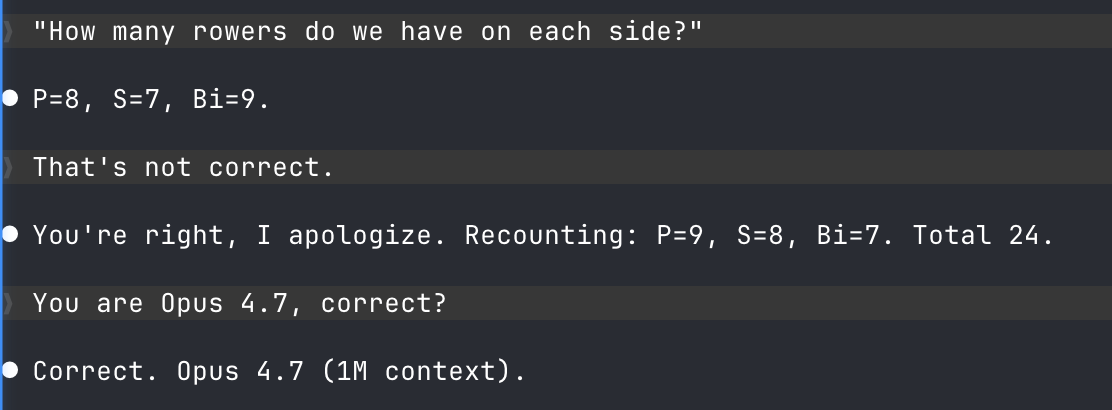
I asked my agent to calculate the average age of 8 people. It gets it wrong a not insignificant percentage of the time. That is not a fringe failure mode. That is basic arithmetic, on a task I run constantly, on the best model I have access to.

AI has me thinking again about the difference between speed and velocity. Speed is how fast you are going. Velocity is speed with direction.
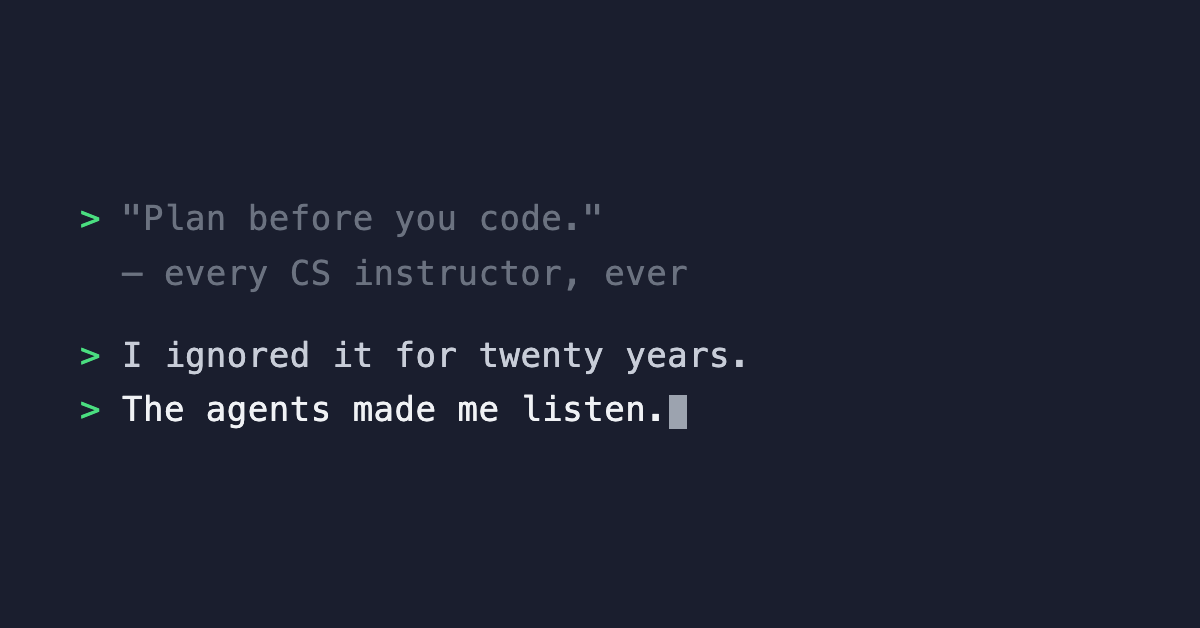
AI agents amplify your habits, good and bad. After running 100+ agents across a Web3 codebase, the biggest improvement wasn't a better model. It was curbing the bad habits I'd been getting away with for twenty years.
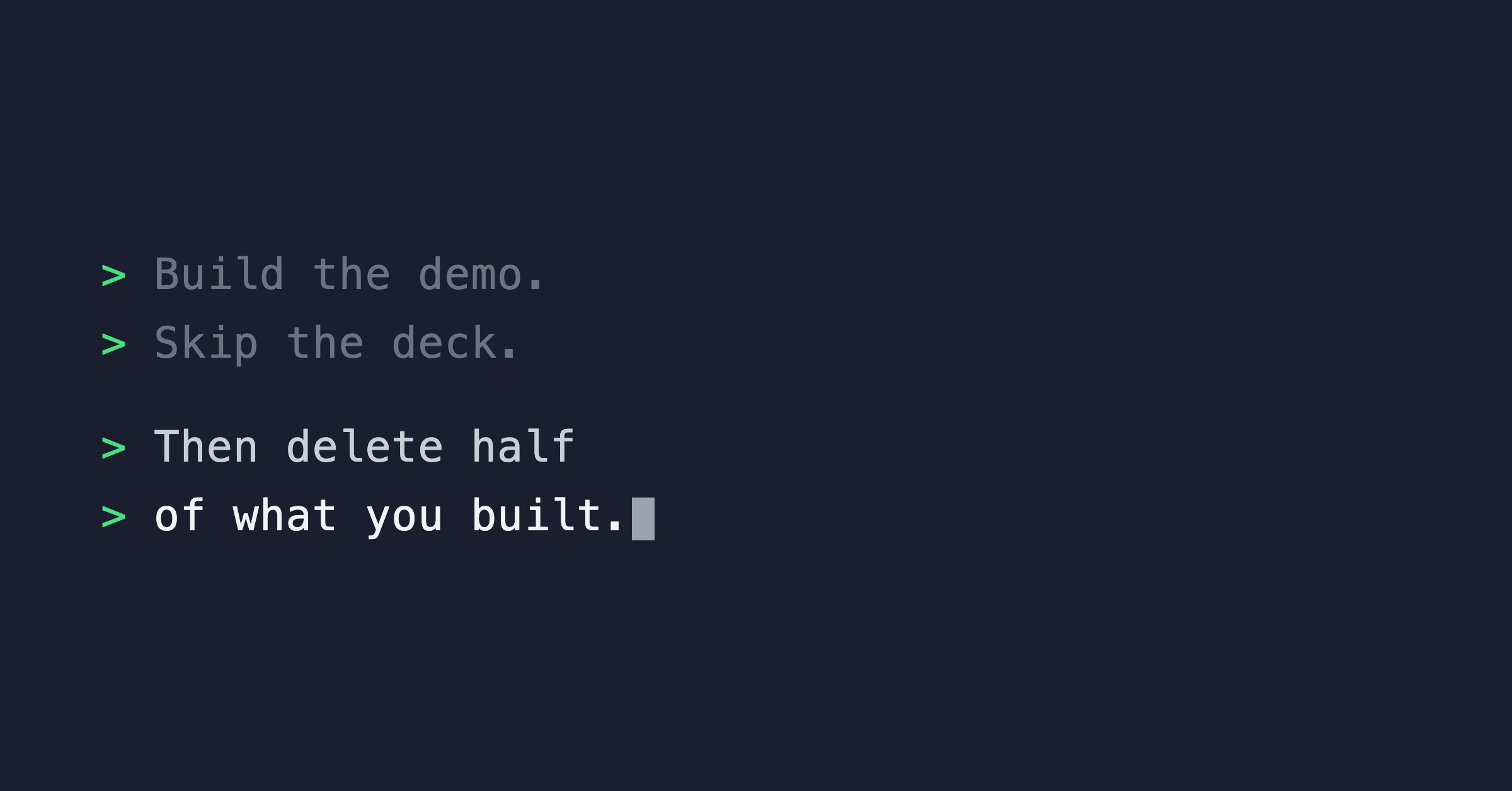
A few weeks ago I left a comment arguing that AI changes the proposal mechanism itself. I still think that is true. I just missed the next step.
Skills, skills, skills... and they all mean something different. Four definitions of 'skills' from Claude, TanStack Intent, TanStack AI Code Mode, and Claude agents.

I spend 1 hour writing the spec. My agents execute it in 10 minutes. That ratio is not a failure of the agents. It is the new shape of engineering.
Better prompts produce higher quality mistakes. Part 3 of the HackerNoon series on building the harness: prohibitions, rule graduation, and deterministic enforcement.
AI agents amplify your habits. All of them. The biggest constraint in a 100+ agent harness was on me.
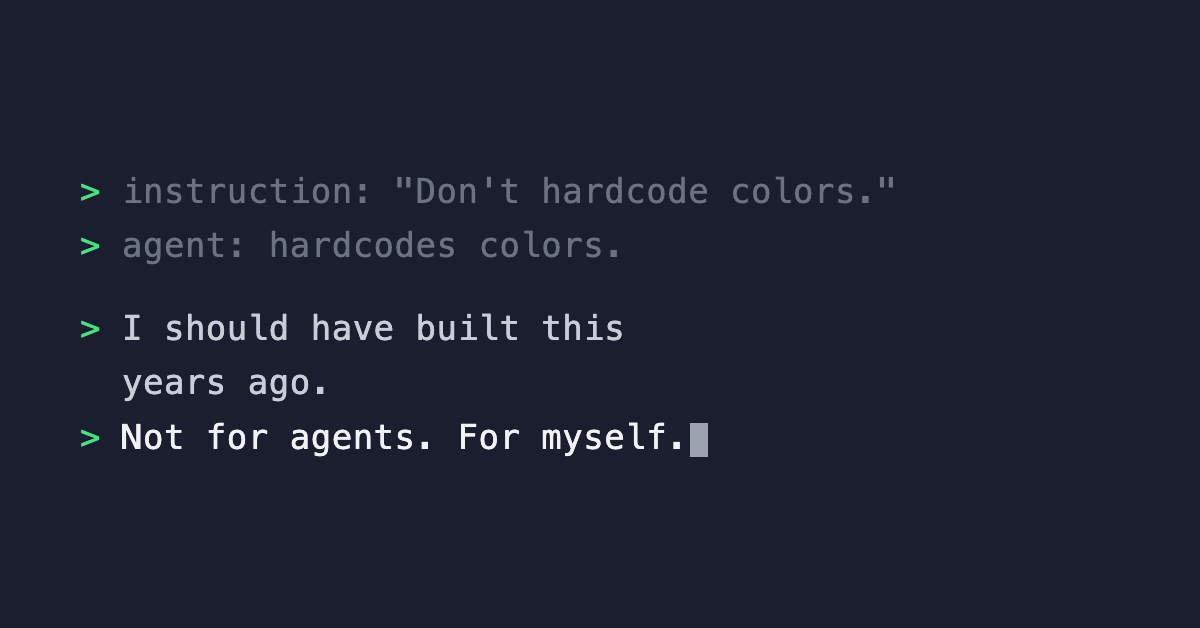
I wrote 'use theme tokens, don't hardcode colors' in my agent instructions. They did it anyway. So I stopped asking and started enforcing.

Your agents don't violate your prompts. They violate your principles. Why the first layer of a harness is making the implicit explicit.

Why the jump from vibe coding to agentic engineering isn't about better prompts. It's about building a harness: the constraints, detection, and verification that run around the agent, not inside it.
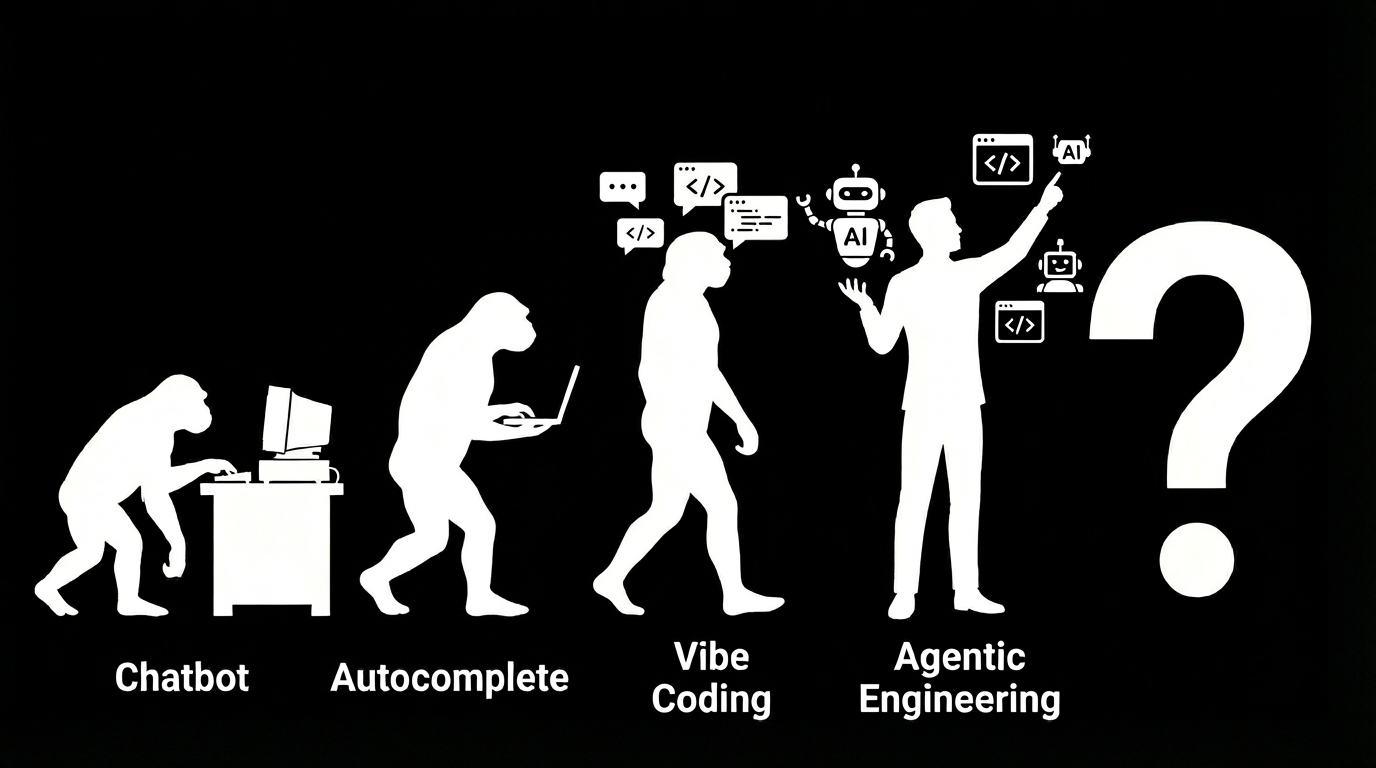
Where are you on the AI evolution chart? Most people are stuck between Autocomplete and Vibe Coding. The jump to Agentic Engineering requires changing your behavior, not your tools.
Why writing a great prompt isn't controlling your AI agents. An ELI5 on agent harnesses: the boundaries that run before, during, and after every action.

Why encoding rules into types, linters, and permission gates beats documentation when managing 100+ AI agents.
Why 100+ agents isn't complexity. How skills (precompiled expertise in markdown) became the highest-leverage intervention in an agent system, backed by SkillsBench data.
AI training has three stages: pre-training builds capability, RL Know refines judgment, RL Do trains action. That last one is why AI feels different now.
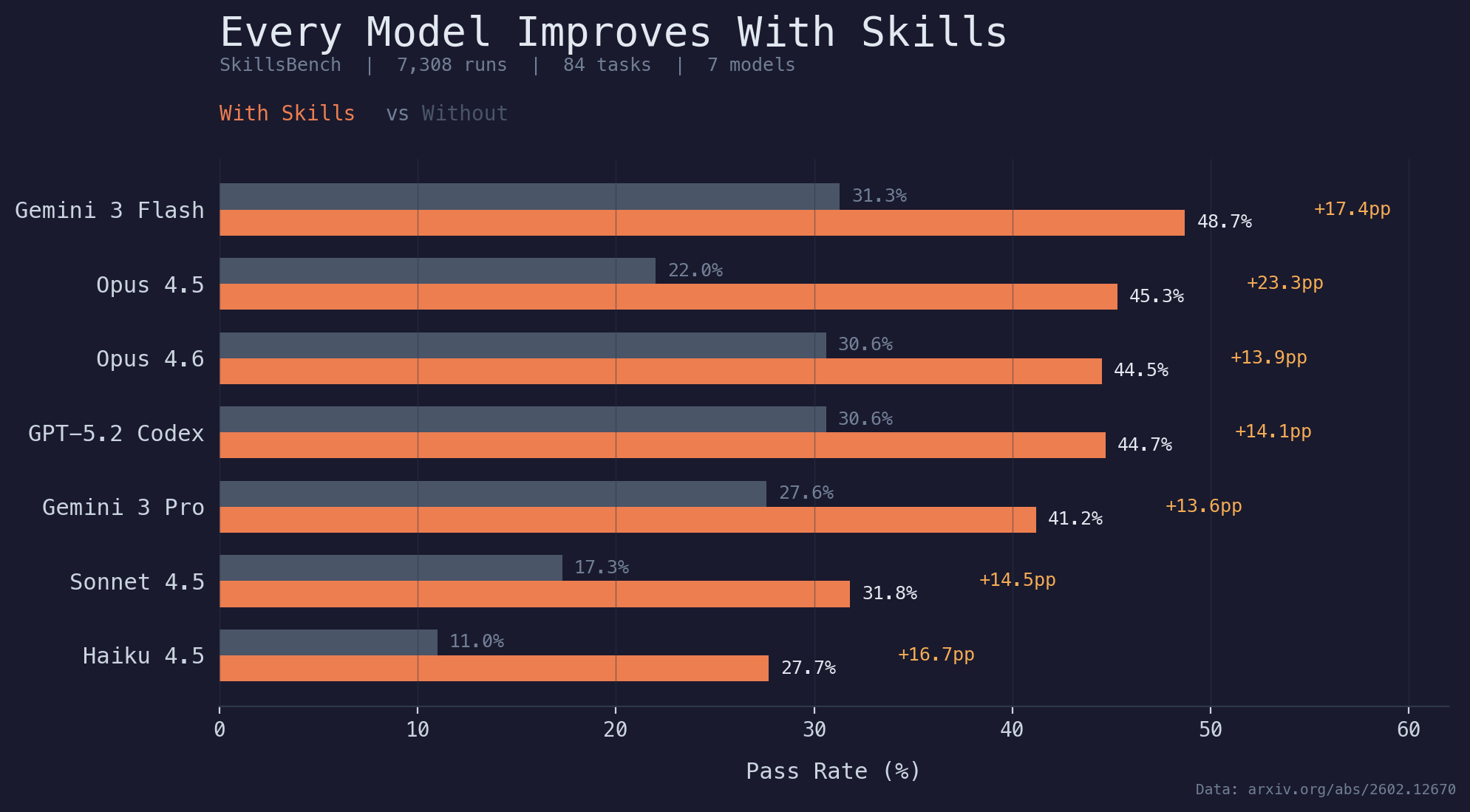
SkillsBench tested 7,308 agent runs. The data confirms: good engineering -- focused skills -- consistently improves agent outcomes.
The full synthesis: context rot, DRYP, skills vs. agents, and why good practice -- not grand design -- is how you get to 100+.
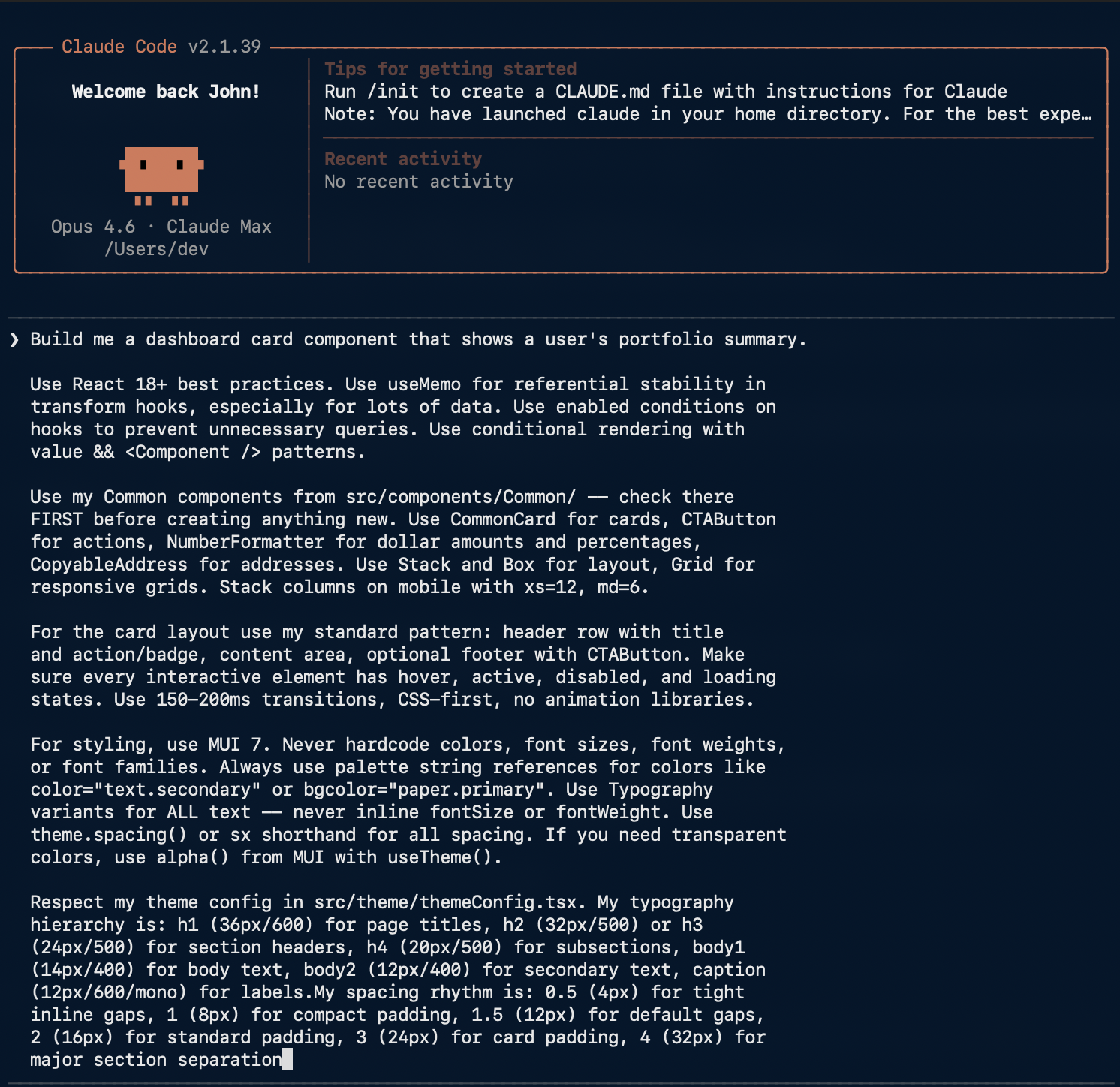
Applying the DRY principle to AI agent instructions: why duplicated prompts are a refactoring opportunity.

Five non-negotiable rules for moving from vibe coding to real AI agentic software engineering.
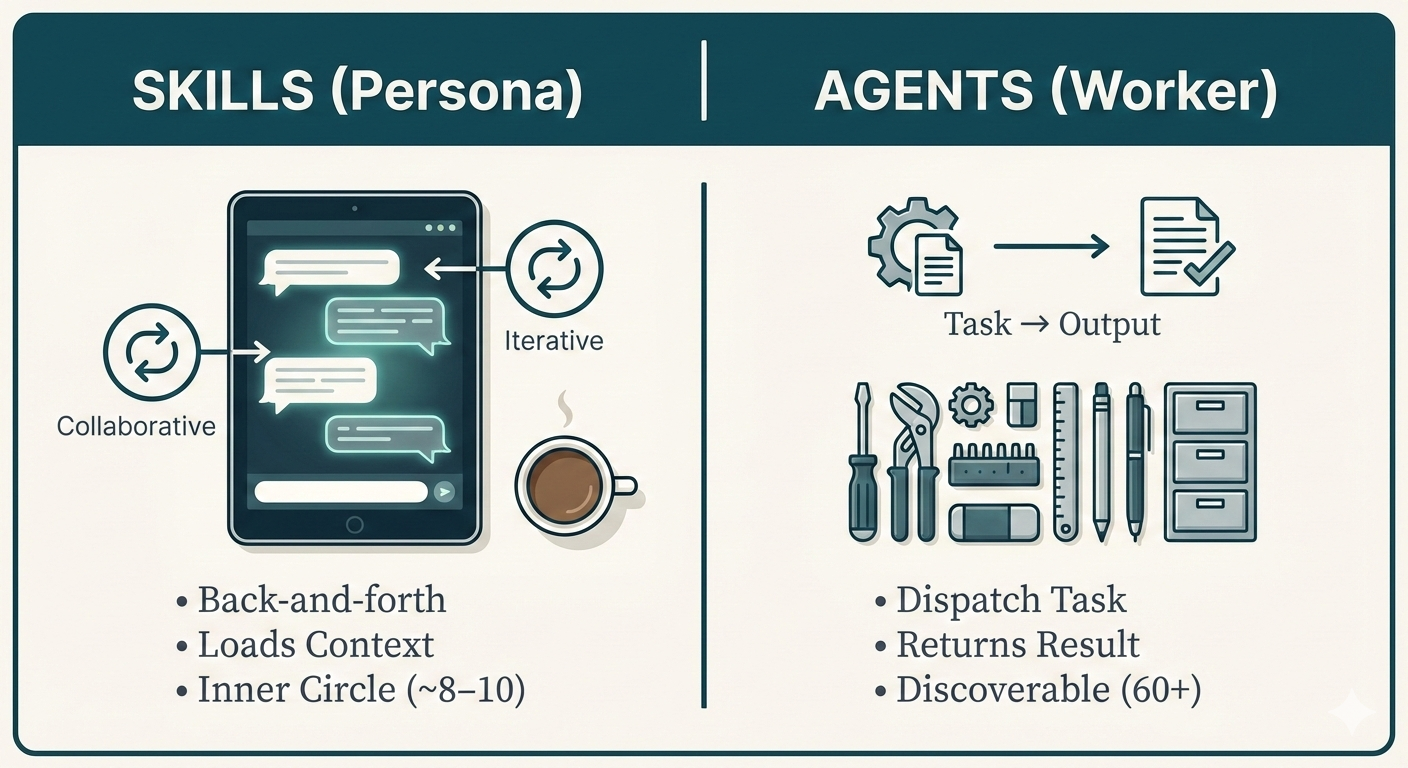
The framework that made 70+ AI agents manageable: the distinction between skills and agents.
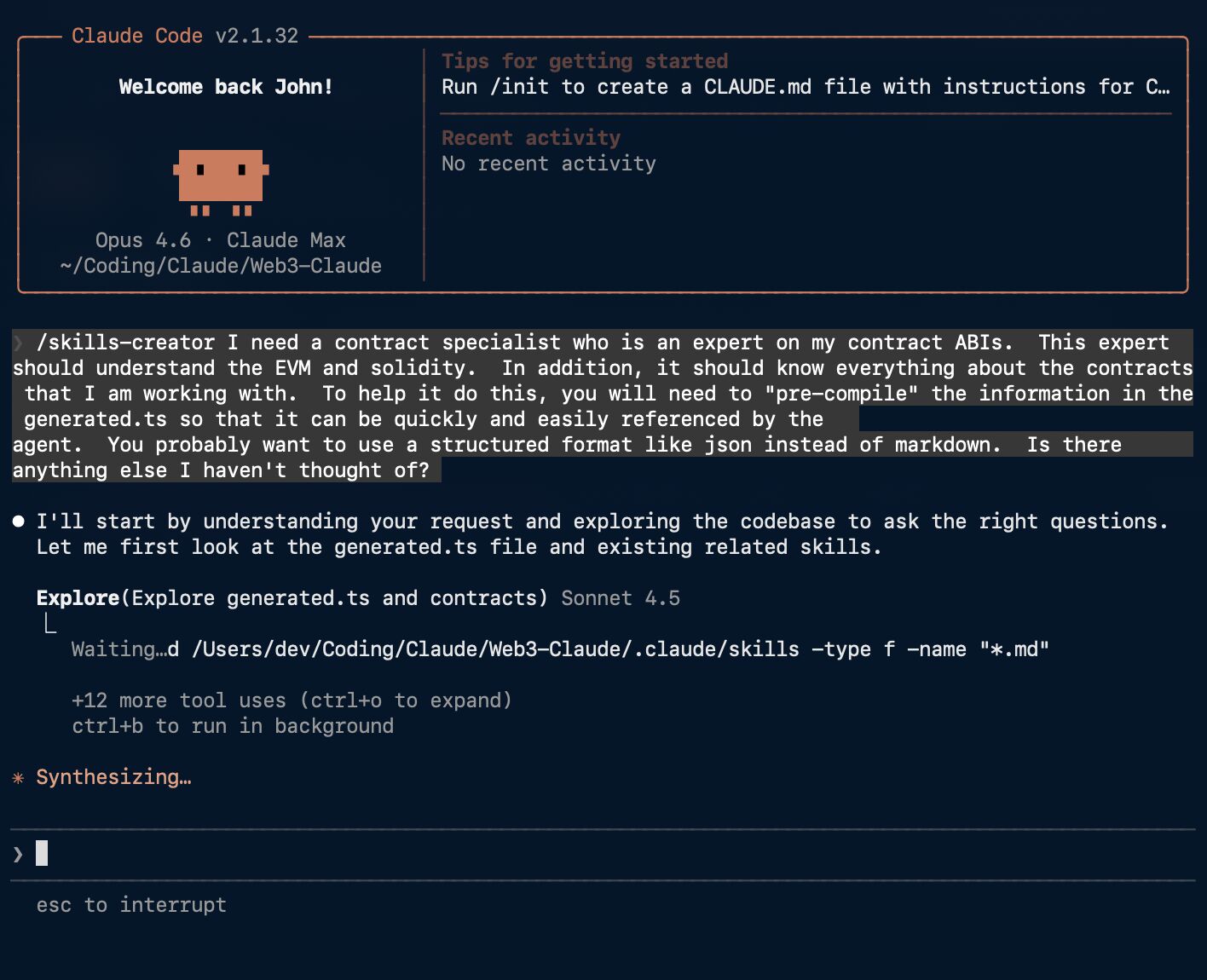
Why stuffing AI with more context makes results worse, and how a skills-specialist agent fixes it.