Why 100 Agents?
I’ve been writing about DRYP and how 100+ agents emerge from refactoring. Now there’s a benchmark that tested the premise at scale.
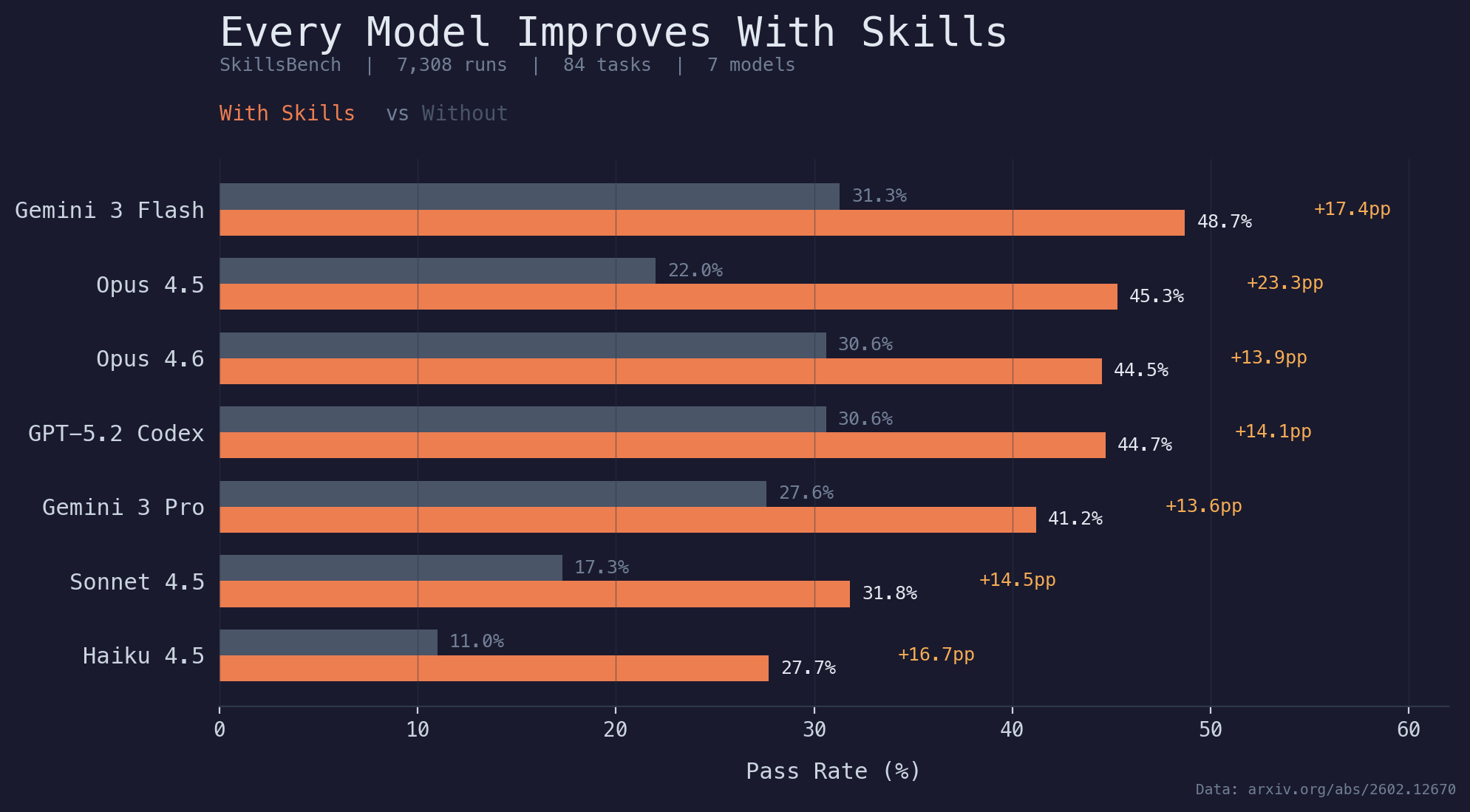
SkillsBench: 7,308 agent runs. 84 tasks. 11 domains. 7 models.
Look at the chart. Every tested model configuration improves with curated skills.
In this benchmark, the data supports what many of us have seen in practice: good engineering - in this case creating finely tuned skills - consistently improves outcomes.
This isn’t vibe coding. We aren’t throwing prompts at a wall and hoping they stick. The same engineering principles that have always worked - modularity, single responsibility, separation of concerns - work here too. Apply them to your agent instructions and the results compound the same way good code always has.
And the compounding follows a pattern: personal tool -> engineering artifact -> business tool the whole team uses.
I built a person-risk-analyzer for vetting DeFi contacts. Adversarial by default - guilty until proven innocent. I cleaned it up the way you’d clean up any function that got unwieldy: clearer interfaces, modular steps, explicit decision criteria. The result is an engineered agent that stacks with other agents like Lego blocks.
Then I plugged it into our company Slack. Now the person who handles partnerships - no engineering background - uses it before every first call. She messages a bot with a name, reads the report, decides whether to proceed. Like all well-engineered products, she doesn’t need to know how it works or what model runs it.
An engineer using a skill saves their own time. A non-engineer using that same skill does something they couldn’t do before. That’s not just efficiency. That’s capability expansion for the whole team.
Good engineering has always compounded. Now it compounds into people who never write code.
What’s one skill file that changed output quality the most for your team?
#AgenticEngineering #AIAgents #BuildInPublic #SkillsBench #LLMs